Warning
You are currently viewing v2.15 of the documentation and it is not the latest. For the most recent documentation, kindly click here.
Scale applications based on a cron schedule.
This specification describes the cron trigger that scales workloads in/out based on a cron Schedule.
triggers:
- type: cron
metadata:
# Required
timezone: Asia/Kolkata # The acceptable values would be a value from the IANA Time Zone Database.
start: 0 6 * * * # At 6:00 AM
end: 0 20 * * * # At 8:00 PM
desiredReplicas: "10"
Parameter list:
timezone - One of the acceptable values from the IANA Time Zone Database. The list of timezones can be found here.start - Cron expression indicating the start of the cron schedule.end - Cron expression indicating the end of the cron schedule.desiredReplicas - Number of replicas to which the resource has to be scaled between the start and end of the cron schedule.💡 Note:
start/endsupport “Linux format cron” (Minute Hour Dom Month Dow).
Notice: Start and end should not be same.
For example, the following schedule is not valid:
start: 0 6 * * * # At 6:00 AM end: 0 6 * * * # also at 6:00 AM
The CRON scaler allows you to define a time range in which you want to scale your workloads out/in.
When the time window starts, it will scale from the minimum number of replicas to the desired number of replicas based on your configuration.
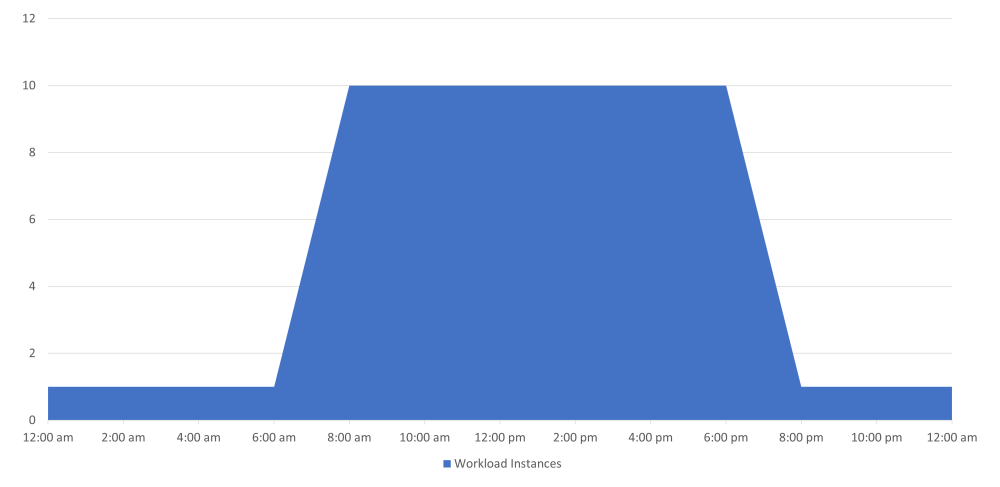
What the CRON scaler does not do, is scale your workloads based on a recurring schedule.
If you want to scale you deployment to 0 outside office hours / working hours,
you need to set minReplicaCount: 0 in the ScaledObject, and increase the
replicas during work hours. That way the Deployment will be scaled to 0 outside
that time window. By default the ScaledObject cooldownPeriod is 5 minutes, so the actual
scaling down will happen 5 minutes after the cron schedule end parameter.
It’s almost always an error to try to do the other way
around, i.e. set desiredReplicas: 0 in the cron trigger.
💡 NOTE: As the HPA Controller will evaluate all the metrics at once and will take the one which requires more instances (
max(metrics)), the value set fordesiredReplicastechnically acts as a “dynamic” minimum replicas. For example, if you have other trigger like CPU, during the time betweenstartandendyou will have AT LEASTdesiredReplicasbecause of thatmax(metrics).
Once a deployment is scaled down to 0 replicas, the checks relying on pod-related metrics are ignored, given that no pods are currently running and these metrics are therefore impossible to retrieve. For this reason, pod-related metrics are also ignored for scaling to zero and this process is done only considering external metrics.
minReplicaCount to 0cron trigger: define start, end and timezone, and set desiredReplicas to the previous value of minReplicaCountScaledObjectapiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
scaleTargetRef:
name: my-deployment
minReplicaCount: 0
cooldownPeriod: 300
triggers:
- type: cron
metadata:
timezone: Asia/Kolkata
start: 0 6 * * *
end: 0 20 * * *
desiredReplicas: "10"
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
scaleTargetRef:
name: my-deployment
minReplicaCount: 0
maxReplicaCount: 4
cooldownPeriod: 300
triggers:
- type: cron
metadata:
timezone: Asia/Kolkata
start: 0 6 * * *
end: 0 20 * * *
desiredReplicas: "1"
- type: cpu
metricType: Utilization
metadata:
value: "80"
The deployment will scale to 0 between 20:00 and 06:00, and will have between 1 and 4 replicas between 06:00 and 20:00.