Warning
You are currently viewing v2.0 of the documentation and it is not the latest. For the most recent documentation, kindly click here.
Azure Log Analytics Click here for latest
Scale applications based on Azure Log Analytics query result
This specification describes the azure-log-analytics trigger for Azure Log Analytics query result. Here is an example of providing values in metadata:
triggers:
- type: azure-log-analytics
metadata:
tenantId: "AZURE_AD_TENANT_ID"
clientId: "SERVICE_PRINCIPAL_CLIENT_ID"
clientSecret: "SERVICE_PRINCIPAL_PASSWORD"
workspaceId: "LOG_ANALYTICS_WORKSPACE_ID"
query: |
let AppName = "web";
let ClusterName = "demo-cluster";
let AvgDuration = ago(10m);
let ThresholdCoefficient = 0.8;
Perf
| where InstanceName contains AppName
| where InstanceName contains ClusterName
| where CounterName == "cpuUsageNanoCores"
| where TimeGenerated > AvgDuration
| extend AppName = substring(InstanceName, indexof((InstanceName), "/", 0, -1, 10) + 1)
| summarize MetricValue=round(avg(CounterValue)) by CounterName, AppName
| join (Perf
| where InstanceName contains AppName
| where InstanceName contains ClusterName
| where CounterName == "cpuLimitNanoCores"
| where TimeGenerated > AvgDuration
| extend AppName = substring(InstanceName, indexof((InstanceName), "/", 0, -1, 10) + 1)
| summarize arg_max(TimeGenerated, *) by AppName, CounterName
| project Limit = CounterValue, TimeGenerated, CounterPath, AppName)
on AppName
| project MetricValue, Threshold = Limit * ThresholdCoefficient
threshold: "1900000000"
# Alternatively, you can use existing environment variables to read configuration from:
# See details in "Parameter list" section
workspaceIdFromEnv: LOG_ANALYTICS_WORKSPACE_ID_ENV_NAME # Optional. You can use this instead of `workspaceId` parameter.
clientIdFromEnv: SERVICE_PRINCIPAL_CLIENT_ID_ENV_NAME # Optional. You can use this instead of `clientId` parameter.
tenantIdFromEnv: AZURE_AD_TENANT_ID_ENV_NAME # Optional. You can use this instead of `tenantId` parameter.
clientSecretFromEnv: SERVICE_PRINCIPAL_PASSWORD_ENV_NAME # Optional. You can use this instead of `clientSecret` parameter.
Parameter list:
tenantId - Id of the Azure Active Directory tenant. Follow this link to retrieve your tenant id.clientId - Id of the application from your Azure AD Application/service principal. Follow this link to create your service principal.clientSecret - Password from your Azure AD Application/service principal.workspaceId - Id of Log Analytics workspace. Follow this link to get your Log Analytics workspace id.query - Log Analytics kusto query, JSON escaped. You can use this tool to convert your query from Log Analytics query editor to JSON escaped string, and then review YAML specific escapes.threshold - Value that is used as a threshold to calculate # of pods for scale target.The authentication parameters could be provided using environmental variables, instead of setting them directly in metadata. Here is a list of parameters you can use to retrieve values from environment variables:
tenantIdFromEnv - An environmental variable name, that stores Azure Active Directory tenant id. Follow this link to retrieve your tenant id. (Optional)clientIdFromEnv - An environmental variable name, that stores Application id from your Azure AD Application/service principal. Follow this link to create your service principal. (Optional)clientSecretFromEnv - An environmental variable name, that stores password from your Azure AD Application/service principal. (Optional)workspaceIdFromEnv - An environmental variable name, that stores your Log Analytics workspace id. Follow this link to get your Log Analytics workspace id. (Optional)💡 NOTE: The workspaceID for Log Analytics is called the
customerId; it’s not the fullid! the exampleazcommand below can be used.
az monitor log-analytics workspace list --query '[]. {ResourceGroup:resourceGroup,WorkspaceName:name,"workspaceID (customerId)":customerId}' -o table
It is important to design your query to return 1 table with 1 row. A good practice is to add “| limit 1” at the end of your query.
Scaler will take value from:
You can define threshold in trigger metadata, it will be used if your query results only 1 cell, that will be interpreted as metric value. Be aware, even if you have defined threshold in metadata, it can be overwritten by your query.
A data types of your query result should be: real, int or long. Other data types are not supported. Later, during runtime, your data will be converted to int64.
Be careful with setting up “pollingInterval” and long-running queries. Test your query before.
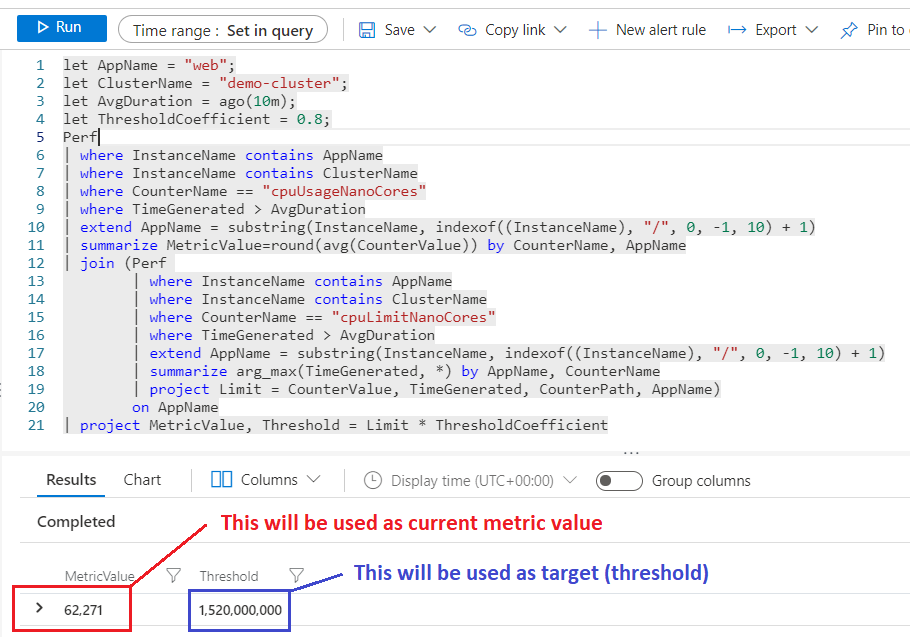
Example query to get MetricValue and Threshold based on CPU usage and limits, defined for the pod.
let AppName = "web";
let ClusterName = "demo-cluster";
let AvgDuration = ago(10m);
let ThresholdCoefficient = 0.8;
Perf
| where InstanceName contains AppName
| where InstanceName contains ClusterName
| where CounterName == "cpuUsageNanoCores"
| where TimeGenerated > AvgDuration
| extend AppName = substring(InstanceName, indexof((InstanceName), "/", 0, -1, 10) + 1)
| summarize MetricValue=round(avg(CounterValue)) by CounterName, AppName
| join (Perf
| where InstanceName contains AppName
| where InstanceName contains ClusterName
| where CounterName == "cpuLimitNanoCores"
| where TimeGenerated > AvgDuration
| extend AppName = substring(InstanceName, indexof((InstanceName), "/", 0, -1, 10) + 1)
| summarize arg_max(TimeGenerated, *) by AppName, CounterName
| project Limit = CounterValue, TimeGenerated, CounterPath, AppName)
on AppName
| project MetricValue, Threshold = Limit * ThresholdCoefficient
Example result:
You can use TriggerAuthentication CRD to configure the authentication by providing a set of Azure Active Directory credentials and resource identifiers.
Service Principal based authentication:
tenantId - Azure Active Directory tenant id. Follow this link to retrieve your tenant id.clientId - Application id from your Azure AD Application/service principal. Follow this link to create your service principal.clientSecret - Password from your Azure AD Application/service principal.workspaceId - Your Log Analytics workspace id. Follow this link to get your Log Analytics workspace id.Managed identity based authentication:
You can use managed identity to request access token for Log Analytics API. The advantage of this approach is that there is no need to store secrets in Kubernetes. Read more about managed identities in Azure Kubernetes Service.
apiVersion: v1
kind: Secret
metadata:
name: kedaloganalytics
namespace: kedaloganalytics
labels:
app: kedaloganalytics
type: Opaque
data:
tenantId: "QVpVUkVfQURfVEVOQU5UX0lE" #Base64 encoded Azure Active Directory tenant id
clientId: "U0VSVklDRV9QUklOQ0lQQUxfQ0xJRU5UX0lE" #Base64 encoded Application id from your Azure AD Application/service principal
clientSecret: "U0VSVklDRV9QUklOQ0lQQUxfUEFTU1dPUkQ=" #Base64 encoded Password from your Azure AD Application/service principal
workspaceId: "TE9HX0FOQUxZVElDU19XT1JLU1BBQ0VfSUQ=" #Base64 encoded Log Analytics workspace id
---
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: trigger-auth-kedaloganalytics
namespace: kedaloganalytics
spec:
secretTargetRef:
- parameter: tenantId
name: kedaloganalytics
key: tenantId
- parameter: clientId
name: kedaloganalytics
key: clientId
- parameter: clientSecret
name: kedaloganalytics
key: clientSecret
- parameter: workspaceId
name: kedaloganalytics
key: workspaceId
---
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: kedaloganalytics-consumer-scaled-object
namespace: kedaloganalytics
labels:
deploymentName: kedaloganalytics-consumer
spec:
scaleTargetRef:
kind: #Optional: Default: Deployment, Available Options: ReplicaSet, Deployment, DaemonSet, StatefulSet
name: kedaloganalytics-consumer
pollingInterval: 30
cooldownPeriod: 30
minReplicaCount: 1
maxReplicaCount: 10
triggers:
- type: azure-log-analytics
metadata:
query: |
let AppName = "web";
let ClusterName = "demo-cluster";
let AvgDuration = ago(10m);
let ThresholdCoefficient = 0.8;
Perf
| where InstanceName contains AppName
| where InstanceName contains ClusterName
| where CounterName == "cpuUsageNanoCores"
| where TimeGenerated > AvgDuration
| extend AppName = substring(InstanceName, indexof((InstanceName), "/", 0, -1, 10) + 1)
| summarize MetricValue=round(avg(CounterValue)) by CounterName, AppName
| join (Perf
| where InstanceName contains AppName
| where InstanceName contains ClusterName
| where CounterName == "cpuLimitNanoCores"
| where TimeGenerated > AvgDuration
| extend AppName = substring(InstanceName, indexof((InstanceName), "/", 0, -1, 10) + 1)
| summarize arg_max(TimeGenerated, *) by AppName, CounterName
| project Limit = CounterValue, TimeGenerated, CounterPath, AppName)
on AppName
| project MetricValue, Threshold = Limit * ThresholdCoefficient
threshold: "1900000000"
authenticationRef:
name: trigger-auth-kedaloganalytics
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: trigger-auth-kedaloganalytics
namespace: kedaloganalytics
spec:
podIdentity:
provider: azure
---
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: kedaloganalytics-consumer-scaled-object
namespace: kedaloganalytics
labels:
deploymentName: kedaloganalytics-consumer
spec:
scaleTargetRef:
kind: #Optional: Default: Deployment, Available Options: ReplicaSet, Deployment, DaemonSet, StatefulSet
name: kedaloganalytics-consumer
pollingInterval: 30
cooldownPeriod: 30
minReplicaCount: 1
maxReplicaCount: 10
triggers:
- type: azure-log-analytics
metadata:
workspaceId: "81963c40-af2e-47cd-8e72-3002e08aa2af"
query: |
let AppName = "web";
let ClusterName = "demo-cluster";
let AvgDuration = ago(10m);
let ThresholdCoefficient = 0.8;
Perf
| where InstanceName contains AppName
| where InstanceName contains ClusterName
| where CounterName == "cpuUsageNanoCores"
| where TimeGenerated > AvgDuration
| extend AppName = substring(InstanceName, indexof((InstanceName), "/", 0, -1, 10) + 1)
| summarize MetricValue=round(avg(CounterValue)) by CounterName, AppName
| join (Perf
| where InstanceName contains AppName
| where InstanceName contains ClusterName
| where CounterName == "cpuLimitNanoCores"
| where TimeGenerated > AvgDuration
| extend AppName = substring(InstanceName, indexof((InstanceName), "/", 0, -1, 10) + 1)
| summarize arg_max(TimeGenerated, *) by AppName, CounterName
| project Limit = CounterValue, TimeGenerated, CounterPath, AppName)
on AppName
| project MetricValue, Threshold = Limit * ThresholdCoefficient
threshold: "1900000000"
authenticationRef:
name: trigger-auth-kedaloganalytics
Use the following commands to create user defined identity, role assignment to Azure Log Analytics and deploy\update KEDA:
export SUBSCRIPTION_ID="<SubscriptionID>"
export RESOURCE_GROUP="<AKSResourceGroup>"
export CLUSTER_NAME="<AKSClusterName>"
export CLUSTER_LOCATION="<AKSClusterLocation>" # "westeurope", "northeurope"...
export IDENTITY_NAME="<SomeName>" #Any name
export LOG_ANALYTICS_RESOURCE_ID="<LAResourceID>"
# Login to Azure, set subscription, get AKS credentials
az login
az account set -s "${SUBSCRIPTION_ID}"
az aks get-credentials -n ${CLUSTER_NAME} -g ${RESOURCE_GROUP}
# ------- Cluster preparation. Run this block only once for fresh cluster.
# Clone repo and run initial role assignment
git clone https://github.com/Azure/aad-pod-identity.git
./aad-pod-identity/hack/role-assignment.sh
#Deploy aad-pod-identity using Helm 3
helm repo add aad-pod-identity https://raw.githubusercontent.com/Azure/aad-pod-identity/master/charts
helm repo update
helm install aad-pod-identity aad-pod-identity/aad-pod-identity --namespace=kube-system
# -------------------------------------------------------------------------------------------
#Create identity
az identity create -g ${RESOURCE_GROUP} -n ${IDENTITY_NAME}
export IDENTITY_CLIENT_ID="$(az identity show -g ${RESOURCE_GROUP} -n ${IDENTITY_NAME} --query clientId -otsv)"
export IDENTITY_RESOURCE_ID="$(az identity show -g ${RESOURCE_GROUP} -n ${IDENTITY_NAME} --query id -otsv)"
#Assign reader permissions for your identity to Log Analytics workspace
#WARNING: It can take some time while identity will be provisioned.
#If you see an error: "Principal SOME_ID does not exist in the directory SOME_ID", just wait couple of minutes and then retry.
az role assignment create --role "Log Analytics Reader" --assignee ${IDENTITY_CLIENT_ID} --scope ${LOG_ANALYTICS_RESOURCE_ID}
# Allow cluster to control identity created earlier.
ID="$(az aks show -g ${RESOURCE_GROUP} -n ${CLUSTER_NAME} --query servicePrincipalProfile.clientId -otsv)"
if [[ "${ID:-}" == "msi" ]]; then
ID="$(az aks show -g ${RESOURCE_GROUP} -n ${CLUSTER_NAME} --query identityProfile.kubeletidentity.clientId -otsv)"
fi
az role assignment create --role "Managed Identity Operator" --assignee "${ID}" --scope "${IDENTITY_RESOURCE_ID}"
# Create AzureIdentity and AzureIdentityBinding
cat <<EOF | kubectl apply -f -
apiVersion: "aadpodidentity.k8s.io/v1"
kind: AzureIdentity
metadata:
name: ${IDENTITY_NAME}
spec:
type: 0
resourceID: ${IDENTITY_RESOURCE_ID}
clientID: ${IDENTITY_CLIENT_ID}
EOF
cat <<EOF | kubectl apply -f -
apiVersion: "aadpodidentity.k8s.io/v1"
kind: AzureIdentityBinding
metadata:
name: ${IDENTITY_NAME}-binding
spec:
azureIdentity: ${IDENTITY_NAME}
selector: ${IDENTITY_NAME}
EOF
# APPLY LABELS: OPTION 1
#deploy KEDA using helm chart and specify aadPodIdentity label.
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
helm install keda kedacore/keda --namespace keda --create-namespace --set podIdentity.activeDirectory.identity=${IDENTITY_NAME}
# APPLY LABELS: OPTION 2
#Instead of redeploying KEDA, you can update existing deployment:
kubectl patch deployment keda-operator -n keda --type json -p='[{"op": "add", "path": "/spec/template/metadata/labels/aadpodidbinding", "value": "'${IDENTITY_NAME}'"}]'
kubectl patch deployment keda-metrics-apiserver -n keda --type json -p='[{"op": "add", "path": "/spec/template/metadata/labels/aadpodidbinding", "value": "'${IDENTITY_NAME}'"}]'