Introducing PredictKube - an AI-based predictive autoscaler for KEDA made by Dysnix
Daniel Yavorovych (Dysnix), Yuriy Khoma (Dysnix), Zbynek Roubalik (KEDA), Tom Kerkhove (KEDA)
February 14, 2022
Introducing PredictKube—an AI-based predictive autoscaler for KEDA made by Dysnix
Dysnix has been working with high-traffic backend systems for a long time, and the efficient scaling demand is what their team comes across each day. The engineers have understood that manually dealing with traffic fluctuations and preparations of infrastructure is inefficient because you need to deploy more resources before the traffic increases, not at the moment the event happens. This strategy is problematic for two reasons: first, because it’s often too late to scale when traffic has already arrived and second, resources will be overprovisioned and idle during the times that traffic isn’t present.
And when it comes to deciding how to wrap up this solution, Dysnix decided to rely on KEDA as it is the most universal and applicable component for application autoscaling in Kubernetes.
KEDA is being used as a component on the client side of PredictKube that is responsible for transferring requests and scaling replicas.
Dysnix’s PredictKube integrates with KEDA
Dysnix has built PredictKube, a solution that can be used as a KEDA scaler that is responsible for resource balancing, and an AI model that has learned to react proactively to patterns of traffic activity, to help with both in-time scaling and solving the problem of overprovision.
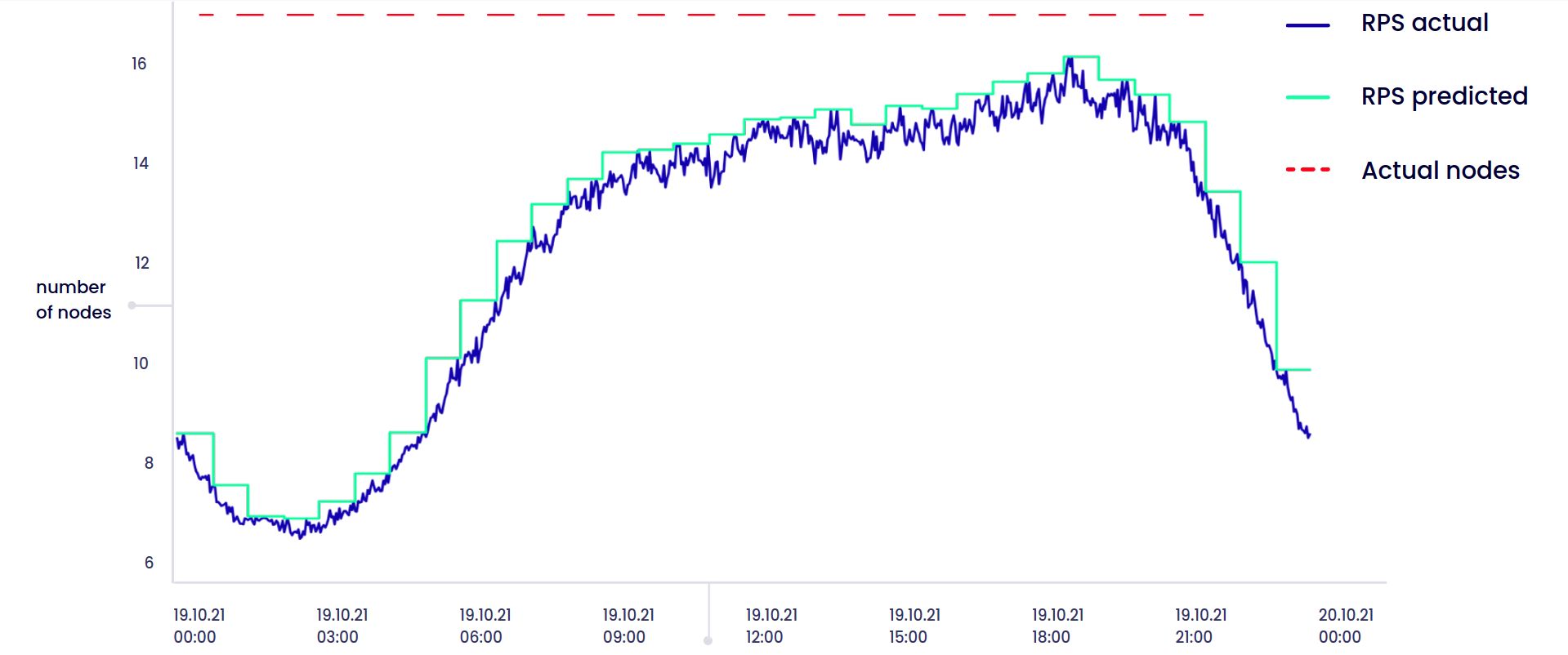
The predictive autoscaling process is possible thanks to an AI model that observes the requests-per-second (RPS) or CPU values for a period of time during a project and then shows the trend for up to 6 hours. PredictKube used customer and open data sources (we used data sets like HTTP NASA logs) to train the model and be specific about the cloud data and traffic trends.
With this tool, Dysnix wants to decrease costs on the projects, analyze the data about traffic more efficiently, use cloud resources more responsibly, and build infrastructures that are "greener" and more performative (with fewer downtimes and delays) than others.
How does PredictKube work?
PredictKube works in two parts:
- On the KEDA side The interface connects via API to the data sources about your traffic. PredictKube uses Prometheus—the industry standard for storing metrics. There, it anonymizes the data about the traffic on the client’s side before sending it to the API, where the model then works with information that is completely impersonal.
- On the AI model side Next, it is linked with a prediction mechanism—the AI model starts to get data about things that happen in your cloud project. Unlike standard rules-based algorithms such as Horizontal Pod Autoscaling (HPA), PredictKube uses Machine Learning models for time series data predicting, like CPU or RPS metrics.
The more data you can provide to it from the start, the more precise the prediction will be. The 2+ weeks data will be enough for the beginning.

The rest is up to you! You can visualize the trend of prediction in, for example, Grafana.
Launch of PredictKube
- Install KEDA
- Get PredictKube API Key
- Go to the PredictKube website
- Register to get the API key in your email
- Create PredictKube Credentials secret
API_KEY="<change-me>"
$ kubectl create secret generic predictkube-secrets --from-literal=apiKey=${API_KEY}
- Configure Predict Autoscaling
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: keda-trigger-auth-predictkube-secret
spec:
secretTargetRef:
- parameter: apiKey
name: predictkube-secrets
key: apiKey
---
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: example
spec:
scaleTargetRef:
name: example-app
pollingInterval: 60
cooldownPeriod: 300
minReplicaCount: 3
maxReplicaCount: 50
triggers:
- type: predictkube
metadata:
predictHorizon: "2h"
historyTimeWindow: "7d" # We recommend using a minimum of a 7-14 day time window as historical data
prometheusAddress: http://kube-prometheus-stack-prometheus.monitoring:9090
query: sum(irate(http_requests_total{pod=~"example-app-.*"}[2m]))
queryStep: "2m" # Note: query step duration for range prometheus queries
threshold: '2000' # Value to start scaling for
authenticationRef:
name: keda-trigger-auth-predictkube-secret
- Check the status and get stats
To check the configuration and status of the scaling created in the previous step, use the following command:
$ kubectl get scaledobject example
To get stats to use for the scaling, use the following command:
$ kubectl get hpa example
Now you can look at how scaling works at a graph in your visualization tool. This is an example of a graph Dysnix gets in one of their projects after using PredictKube:
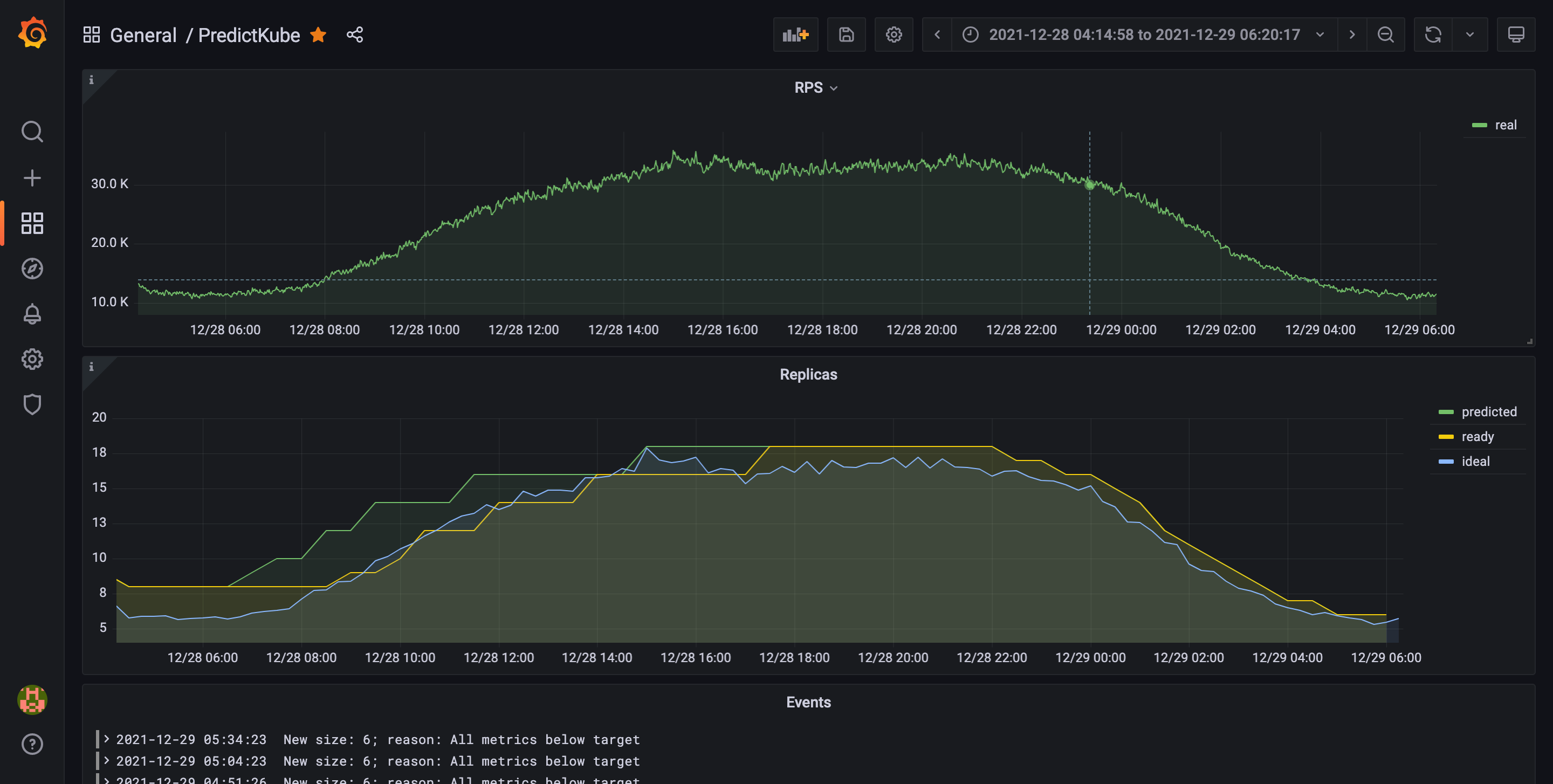
On this graph, you’ll see the graphs of stats for the environment with 2 hours cooldown period. The green trend shows predicted replicas number, a yellow one—ready replicas at a certain moment, and the ideal—the blue trend—showing the closest replicas number covering the RPS trend. If you need a template of such a dashboard to make your own, feel free to contact Daniel to get one.
After everything is connected and deployed, you’ll be able to change the time frame you’re observing or just monitor the data as it comes.
What’s next?
With this release, Dysnix has created the first milestone of predictive autoscaling for Kubernetes workloads. The team hopes you’ll find it interesting and help to test it and improve it. If you have any questions to ask about the core functionality of PredictKube, you may contact the developers’ team here. And for all KEDA-related issues, share your feedback via GitHub.
In the future, PredictKube plans to add more integrations with other data sources to autoscale based on other configurations of the projects. Also, there is an idea for implementing an event-based predictive scaling to make it possible to react on not only a trend but event appearance.
You can contact the Dysnix team with any questions concerning the mechanics of PredictKube or learn more about the data usage in its privacy policy. The following people will be happy to help:
- Daniel Yavorovych — KEDA integration and Kubernetes-related questions;
- Yurij Khoma — can comment more about the AI model that was created.
Thanks for reading,
Daniel Yavorovych and Yuriy Khoma on behalf of the PredictKube developers team.
Recent posts
Google Cloud deprecationsKEDA is graduating to CNCF Graduated project 🎉
Securing autoscaling with the newly improved certificate management in KEDA 2.10
Help shape the future of KEDA with our survey 📝
Announcing KEDA v2.9 🎉
HTTP add-on is looking for contributors by end of November
Announcing KEDA v2.8 🎉
How Zapier uses KEDA
Introducing PredictKube - an AI-based predictive autoscaler for KEDA made by Dysnix
How CAST AI uses KEDA for Kubernetes autoscaling
Announcing KEDA HTTP Add-on v0.1.0
Autoscaling Azure Pipelines agents with KEDA
Why Alibaba Cloud uses KEDA for application autoscaling
Migrating our container images to GitHub Container Registry
Announcing KEDA 2.0 - Taking app autoscaling to the next level
Give KEDA 2.0 (Beta) a test drive
Kubernetes Event-driven Autoscaling (KEDA) is now an official CNCF Sandbox project 🎉