How CAST AI uses KEDA for Kubernetes autoscaling
Žilvinas Urbonas (CAST AI), Annie Talvasto (CAST AI), and Tom Kerkhove (KEDA)
August 4, 2021
How CAST AI uses KEDA for Kubernetes autoscaling
Kubernetes comes with several built-in autoscaling mechanisms - among them the Horizontal Pod Autoscaler (HPA). Scaling is essential for the producer-consumer workflow, a common use case in the IT world today. It’s especially useful for monthly reports and transactions with a huge load where teams need to spin up many workloads to process things faster and cheaper (for example, by using spot instances).
Based on the provided CPU and memory-based metrics, the HPA can scale a setup up by adding more replicas - or down by removing idle replicas (this mechanism is called in/out). But it doesn’t have access to a source of metrics by default. The default HPA features aren’t flexible enough to cover custom scenarios like the producer/consumer.
This is where KEDA comes in.
Optimizing Kubernetes workloads for cost efficiency is the core mission of CAST AI. The platform helps teams reduce their cloud bills by up to 50% with no extra DevOps effort by automatically selecting optimal instances for running clusters, using spot instances whenever possible, and - of course - autoscaling with the help of KEDA.
By automating routine DevOps tasks via Terraform or CLI, CAST AI saves teams many hours they would spend on researching, installing, maintaining, patching, and observing their Kubernetes infrastructure. It also helps to prevent downtime with its multi-cloud capabilities.
KEDA & Horizontal Pod Autoscaler
KEDA is available as a Policy/Add-on for clusters running in CAST AI. Users can easily install it by enabling the Horizontal Pod Autoscaler (HPA) policy in the console’s interface.
KEDA includes two components:
- operator - it watches Kubernetes for ScaledObject resources and configures the HPA accordingly,
- metrics-apiserver - this is a bridge between Kubernetes and various scaling sources (including Prometheus).
These two components configure the HPA and set up custom metric sources, helping teams to autoscale almost any workload: Deployment, ReplicaSet, ReplicationController, or StatefulSet. KEDA supports autoscaling Jobs too.
Enabling KEDA in CAST AI
To autoscale with the Horizontal Pod Autoscaler, users need to enable the KEDA add-on on the Policies page available for every cluster in CAST AI.
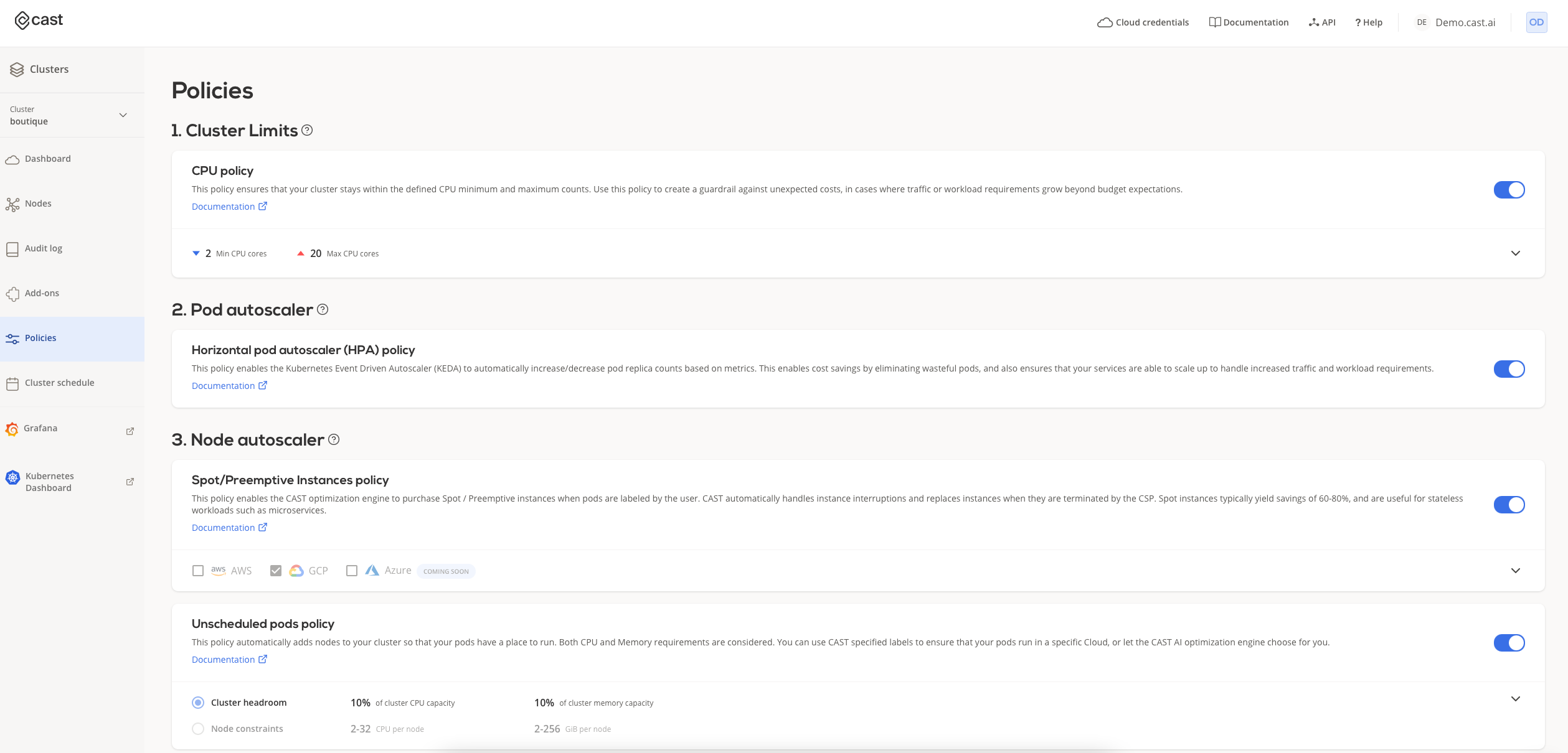
Once enabled, KEDA will start working on a given cluster once users configure the associated scaled object. KEDA automatically changes pod replica counts based on the provided metrics.
Use case 1: Autoscaling based on CPU and/or Memory usage
Let’s imagine that a user created a Deployment and a Service that they want to autoscale.
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-app
labels:
app: sample-app
spec:
# Note that we omit the replica count so
# when we redeploy, we wouldn't override
# replica count set by the autoscaler
#replicas: 1
selector:
matchLabels:
app: sample-app
template:
metadata:
labels:
app: sample-app
spec:
containers:
- image: luxas/autoscale-demo:v0.1.2
name: sample-app
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: sample-app
labels:
app: sample-app
spec:
ports:
- port: 8080
name: http
targetPort: 8080
protocol: TCP
selector:
app: sample-app
Note that the user doesn’t specify a particular ReplicaCount.
Now it’s time to set up a CPU-based Autoscaler:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: sample-app
spec:
scaleTargetRef:
name: sample-app
minReplicaCount: 1 # Optional. Default: 0
maxReplicaCount: 10 # Optional. Default: 100
triggers:
# Either of the triggers can be omitted.
- type: cpu
metadata:
# Possible values: `Value`, `Utilization`, or `AverageValue`.
# More info at: https://keda.sh/docs/latest/scalers/cpu/#trigger-specification
type: "Value"
value: "30"
- type: memory
metadata:
# Possible values: `Value`, `Utilization`, or `AverageValue`.
# More info at: https://keda.sh/docs/latest/scalers/memory/
type: "Value"
value: "512"
Deployment autoscaling will be triggered by CPU or Memory usage. Users can specify any other trigger or remove the triggers altogether - for example, to autoscale only on the basis of the CPU or only using the Memory trigger.
Use case 2: Autoscaling based on a Prometheus metric
CAST AI users can also autoscale their clusters based on the results of arbitrary Prometheus queries. CAST AI clusters come with Prometheus deployed out-of-the-box.
So, let’s deploy a sample application again - but this time, we’ll instruct Prometheus to scrape some metrics:
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-app
labels:
app: sample-app
spec:
selector:
matchLabels:
app: sample-app
template:
metadata:
labels:
app: sample-app
annotations:
# These annotations the main difference!
prometheus.io/path: "/metrics"
prometheus.io/port: "8080"
prometheus.io/scrape: "true"
spec:
containers:
- image: luxas/autoscale-demo:v0.1.2
name: sample-app
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: sample-app
labels:
app: sample-app
spec:
ports:
- port: 8080
name: http
targetPort: 8080
protocol: TCP
selector:
app: sample-app
Then the user can deploy the Autoscaler.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: sample-app
spec:
scaleTargetRef:
name: sample-app
minReplicaCount: 1 # Optional. Default: 0
maxReplicaCount: 10 # Optional. Default: 100
triggers:
- type: prometheus
metadata:
serverAddress: http://prom.castai:9090
threshold: '1'
# Note: query must return a vector/scalar single element response
query: sum(rate(http_requests_total{app="sample-app"}[2m]))
Let’s check whether it all works by generating some load. You can see how the replica count increases.
# Deploy busybox image
kubectl run -it --rm load-generator --image=busybox /bin/sh
# Hit ENTER for command prompt
# trigger infinite requests to the php-apache server
while true; do wget -q -O- http://sample-app:8080/metrics; done
# in order to cancel, hold CTRL+C
# in order to quit, initiate CTRL+D sequence
Batch processing with spot instances & KEDA
Let’s go back to the producer-consumer problem we talked about earlier. Imagine that your company needs to process a large set of invoices at the end of each month. Your team has to spin up many workloads to process these jobs faster.
You switch on the Pod Autoscaler policy and then turn to the KEDA configuration.
Note: The KEDA-based setup can also be used with CAST AI’s cluster autoscaler and spot instances to scale compute-intensive workloads in a cost-effective way. This is done by enabling the Unschedulable pods and Spot Instances policies. By enabling the node deletion policy, users ensure that idle instances are removed immediately.
The policy settings above will help to achieve cost savings for workloads like batch data processing. By moving data processing jobs to spot instances, teams can reduce their cloud bills and become more cloud-agnostic.
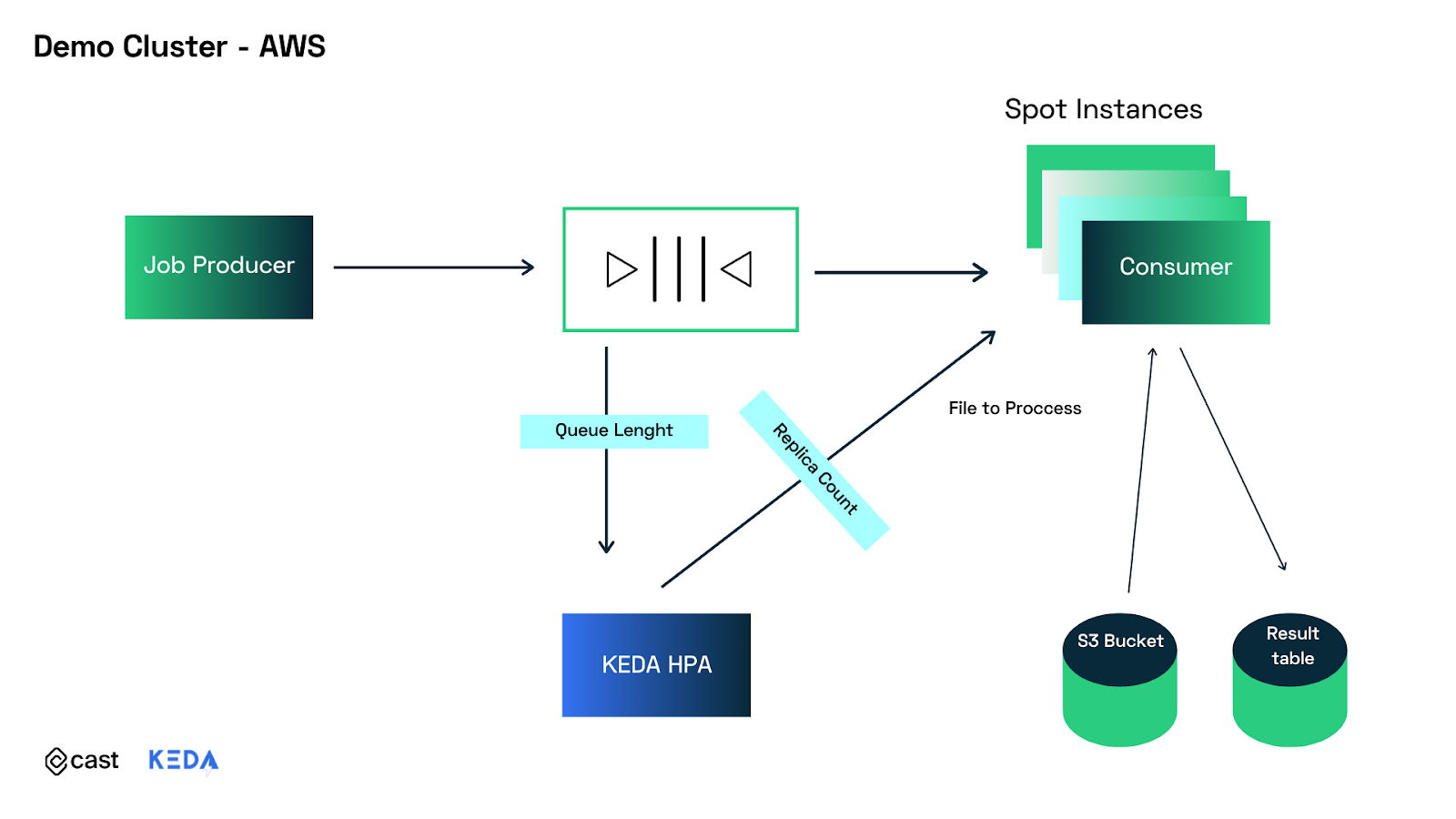
In the system depicted above, we simulated a real-world scenario of producer-consumer-based work processing. The queue length triggers our built-in KEDA component to create pods used to process jobs stored in the queue. These pods are all scheduled on spot instances. When jobs are done, empty nodes are deleted.
CAST AI handles potential spot instance interruptions gracefully. If an interruption occurs and a job is in-flight, the job is marked as failed and reschedules on another node.
Looking towards the future with KEDA
KEDA is an extremely powerful tool for scaling workloads horizontally. It allows workloads to scale to zero, taking up no resources when a job/process is not required. KEDA handles higher-order metrics with ease, enabling the next generation of auto-scaling solutions at CAST AI.
So, where are we going with KEDA next? One of the challenges to solve automatically is choosing scaling parameters. Settings such as minReplicaCount and maxReplicaCount, along with the trigger threshold, have to be set manually today. For the most part, these are educated estimates and trial-and-error experiments performed by the engineering team. CAST AI is working on making these settings more automated based on application performance and the reaction to change in settings.
We believe that is the next great KEDA challenge, so stay tuned for more!
Glossary:
Add-on
An add-on is an application that helps another application perform more tasks or do it better. Apart from KEDA, CAST AI offers access to add-ons like Grafana, Grafana Loki, Evictor, Ingress Nginx, Cert Manager, Kubernetes Dashboard.
Policy
CAST AI users can turn on and manage policies that automate the process of scaling clusters up and down to optimize and reduce costs.
Recent posts
Google Cloud deprecationsKEDA is graduating to CNCF Graduated project 🎉
Securing autoscaling with the newly improved certificate management in KEDA 2.10
Help shape the future of KEDA with our survey 📝
Announcing KEDA v2.9 🎉
HTTP add-on is looking for contributors by end of November
Announcing KEDA v2.8 🎉
How Zapier uses KEDA
Introducing PredictKube - an AI-based predictive autoscaler for KEDA made by Dysnix
How CAST AI uses KEDA for Kubernetes autoscaling
Announcing KEDA HTTP Add-on v0.1.0
Autoscaling Azure Pipelines agents with KEDA
Why Alibaba Cloud uses KEDA for application autoscaling
Migrating our container images to GitHub Container Registry
Announcing KEDA 2.0 - Taking app autoscaling to the next level
Give KEDA 2.0 (Beta) a test drive
Kubernetes Event-driven Autoscaling (KEDA) is now an official CNCF Sandbox project 🎉