Announcing KEDA HTTP Add-on v0.1.0
Aaron Schlesinger and Tom Kerkhove
June 24, 2021
Over the past few months, we’ve been adding more and more scalers to KEDA making it easier for users to scale on what they need. Today, we leverage more than 30 scalers out-of-the-box, supporting all major cloud providers & industry-standard tools such as Prometheus that can scale any Kubernetes resource.
But, we are missing a major feature that many modern, distributed applications need - the ability to scale based on HTTP traffic.
It’s time to change this.
Note: You can build your own custom HTTP autoscaling system using the Prometheus scaler per our FAQ. The new HTTP Addon adds first-class, end-to-end support for HTTP.
Introducing our HTTP add-on for KEDA
Autoscaling HTTP is often not as straightforward as other event sources. You don’t know how much traffic will be coming and, given its synchronous nature, supporting scale-to-zero HTTP applications requires an intelligent intermediate routing layer to “hold” the incoming request(s) until new instances of the backend application are created and running.
We’re happy to announce our experimental HTTP add-on for KEDA which is purely focused on solving this problem. This new project introduces an HTTPScaledObject CRD, which you use to autoscale a Kubernetes Deployment, including scale-to-zero.
We’ve taken a “batteries included with reasonable defaults” approach to designing and building the HTTP add-on. This means that you don’t have to run other tools such as Prometheus. At the same time, the system is made up of well-defined, reusable components that can run independently. You can opt-out of the defaults and customize components as you see fit. In many cases, you can even run most of the components independently.
Scaling based on incoming HTTP traffic is different from core KEDA triggers for two reasons:
- There is no standard existing API you can call to get a counter or other metric to scale on. For example, we cannot call the Kafka API to get the length of a queue.
- You need to set up the infrastructure to route HTTP requests to the server you’re autoscaling
You can see the HTTP add-on as just another trigger in your scaling toolbox.
⚠ Given its experimental state of this project, breaking changes can occur and the HTTP add-on is not supported for production workloads yet.
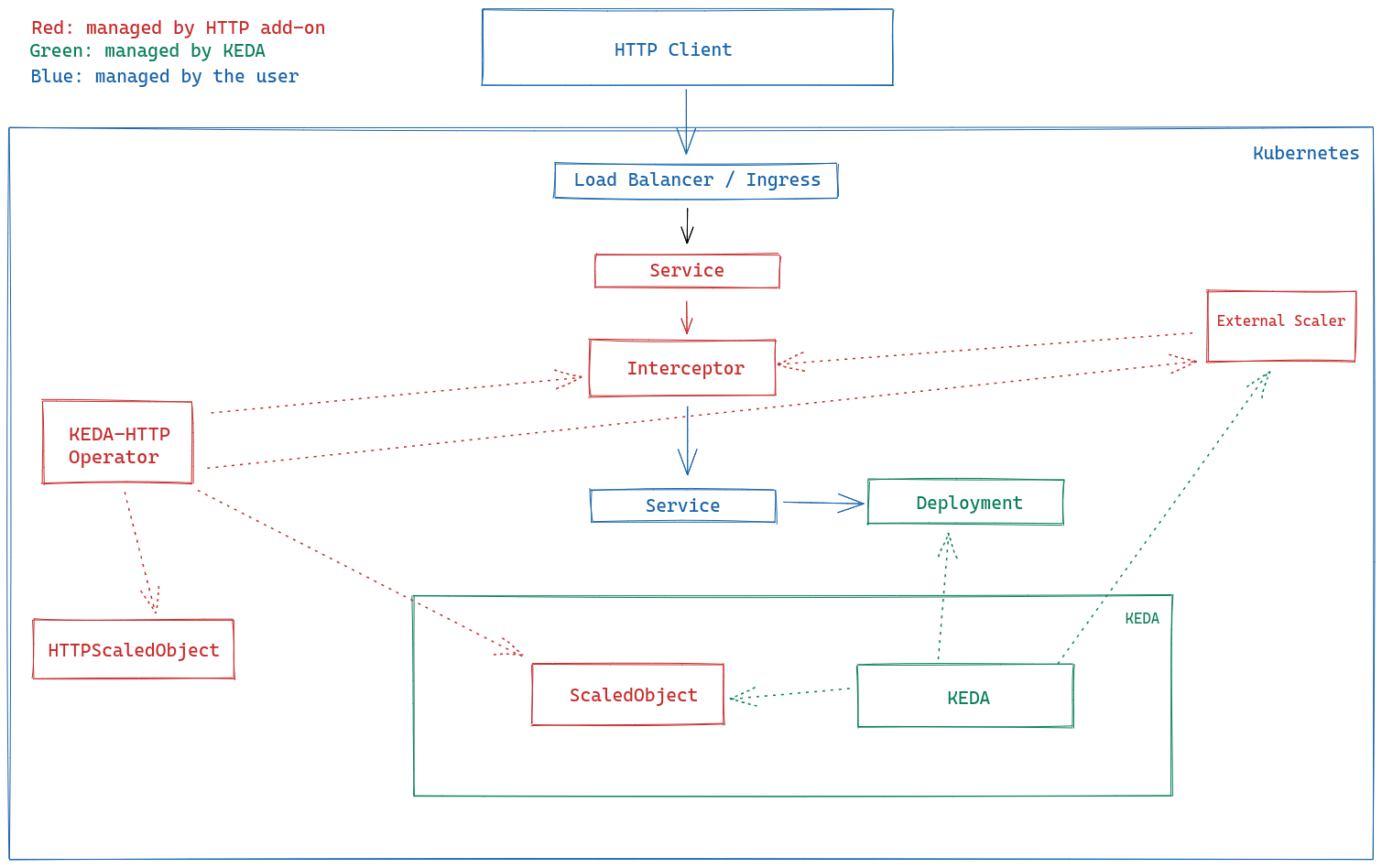
How does it work?
Since KEDA already does an excellent job listening for events and autoscaling, the HTTP add-on simply adds an HTTP-aware layer on top.
The system is made up of 3 components:
- Interceptor: This component accepts HTTP requests into the system, reports pending HTTP request queue metrics to the external scaler, and forwards requests to the target application.
- If the application is currently scaled to zero replicas, the interceptor will hold requests until it scales up
- External scaler: This is an external push scaler that constantly pings the interceptor to get pending HTTP queue metrics. It transforms these data and sends them directly down to KEDA, which then makes a scaling decision
- Operator: This is an Operator that runs for the convenience of the user. It listens for new CRD resources, called
HTTPScaledObjects, and creates and configures interceptors and scalers so that your existingDeploymentwill begin autoscaling according to incoming HTTP traffic.
Seeing it in action
We’ve aimed to make the HTTP add-on approximately as simple to operate and use as KEDA.
There are two major steps to using it:
- Install the KEDA HTTP add-on operator
- Create a new
HTTPScaledObject
Installing the Operator
This is an optional step, but we highly recommend it because the operator makes interacting with the HTTP add-on more convenient. We’ve packaged the operator up in a Helm chart, which you can install by following the instructions below.
The commands below have been tested on Mac and Linux (Ubuntu). They likely work on Windows WSL2, but won’t work on Powershell. You’ll also need to ensure you have access to a Kubernetes cluster with a Kubernetes configuration file properly configured.
Install KEDA
First, make sure you’ve set up an environment variable for the namespace you’d like to install everything into:
export NAMESPACE=mynamespace
Next, install KEDA:
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
helm install --create-namespace -n ${NAMESPACE} keda kedacore/keda
Install the Operator
Now that KEDA is installed, you can install the operator:
helm install --create-namespace -n ${NAMESPACE} http-add-on kedacore/keda-add-ons-http
Install an HTTPScaledObject
The HTTPScaledObject CRD instructs the operator to install and configure the interceptor and scaler for a specified Deployment. For this to work, you’ll need to have a Deployment running in the same $NAMESPACE and a Service configured to route traffic to the pods in that Deployment.
We’ve created a sample application here as a Helm chart for you. It comes complete with a properly configured
HTTPScaledObject, so when you install the chart, everything will be automatically configured for you and you can skip the rest of this section. If you install this chart, you can skip the rest of this section.
After you have your application set up, copy the following YAML into a file called myautoscaledapp.yaml:
kind: HTTPScaledObject
apiVersion: http.keda.sh/v1alpha1
metadata:
name: myapp
spec:
scaleTargetRef:
deployment: myAppDeployment
service: myAppService
port: 8080
And finally, submit it to your Kubernetes cluster:
kubectl create -f -n $NAMESPACE myautoscaledapp.yaml
The operator will pick up the CRD and, when it’s done installing and configuring, you’ll see a new Service (among other things!) that’s ready to route HTTP traffic to your Deployment. Send all of your HTTP to the Service, and the Deployment will begin autoscaling!
Cleaning up
To clean up, remove the HTTPScaledObject you created, then delete the two Helm charts you installed:
kubectl delete -n $NAMESPACE httpscaledobject myapp
helm delete -n ${NAMESPACE} kedahttp
helm delete -n ${NAMESPACE} keda
What’s next?
With this release, we’ve built a solid foundation and are now focusing on testing, quality, and expanding the feature set appropriately.
We encourage you to try the software out in your own non-production Kubernetes clusters and share feedback on what you think and we are open to contributions to make it even better.
Today we support autoscaling any HTTP traffic sent to a Kubernetes Services, but we are planning to support more specific traffic patterns including “north-south” with Ingress or the Gateway API and “east-west” with service-to-service communication or service meshes.
In order to achieve this, we are working with the community to support as many existing products that exist today. For example, we will fully rely on the Service Mesh Interface (SMI) specification which has become a solid industry standard for service-mesh workloads.
But why stop there? We are talking to various SIGs to determine if we need a general Traffic Metrics specification that takes the learnings from SMI spec and apply it to all traffic components for a unified traffic metrics approach in Kubernetes.
We’re also looking for feedback and contributors! Please feel free to submit suggestions or ask questions, and if you’re interested in contributing, see our contributing documentation.
Lastly, we’d like to thank the following folks for building the initial prototype of the HTTP add-on and creating this project:
- Aaron Schlesinger
- Lucas Santos
- Aaron Wislang
- Tom Kerkhove and the rest of the KEDA core Maintainers
Thanks for reading,
Aaron Schlesinger on behalf of the KEDA HTTP Add-on contributors and KEDA maintainers.
Recent posts
Google Cloud deprecationsKEDA is graduating to CNCF Graduated project 🎉
Securing autoscaling with the newly improved certificate management in KEDA 2.10
Help shape the future of KEDA with our survey 📝
Announcing KEDA v2.9 🎉
HTTP add-on is looking for contributors by end of November
Announcing KEDA v2.8 🎉
How Zapier uses KEDA
Introducing PredictKube - an AI-based predictive autoscaler for KEDA made by Dysnix
How CAST AI uses KEDA for Kubernetes autoscaling
Announcing KEDA HTTP Add-on v0.1.0
Autoscaling Azure Pipelines agents with KEDA
Why Alibaba Cloud uses KEDA for application autoscaling
Migrating our container images to GitHub Container Registry
Announcing KEDA 2.0 - Taking app autoscaling to the next level
Give KEDA 2.0 (Beta) a test drive
Kubernetes Event-driven Autoscaling (KEDA) is now an official CNCF Sandbox project 🎉