Autoscaling Azure Pipelines agents with KEDA
Troy Denorme
May 27, 2021
With the addition of Azure Piplines support in KEDA, it is now possible to autoscale your Azure Pipelines agents based on the agent pool queue length.
Self-hosted Azure Pipelines agents are the perfect workload for this scaler. By autoscaling the agents you can create a scalable CI/CD environment.
💡 The number of concurrent pipelines you can run is limited by your parallel jobs.
KEDA will autoscale to the maximum defined in the ScaledObject and does not limit itself to the parallel jobs count defined for the Azure DevOps organization.
What are Azure Pipelines self-hosted agents?
Azure Pipelines jobs can run on different kinds of agents (docs). But if you want full control, you are going to have to use self-hosted agents. Agents are able to run on Linux, macOS or Windows machines and can be packaged in to a container.
When running self-hosted agents on Kubernetes, there is no out-of-the-box support for autoscaling. However, with KEDA v2.3 you can now autoscale your self-hosted agents on Kubernetes based on the amount of pending jobs in your agent pool.
You can run the agents as a Deployment or a Job in Kubernetes and scale them accordingly with a ScaledObject or a ScaledJob.
Deploying a self-hosted agent on Kubernetes as a Deployment
Create the container image
To create a basic Azure Pipelines agent image you can follow the instructions from the official docs.
Deploy on Kubernetes
You can easily deploy the agent as a Kubernetes deployment by using this Kubernetes manifest:
apiVersion: v1
kind: Secret
metadata:
name: azdevops
data:
AZP_TOKEN: <base64 encoded PAT>
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: azdevops-deployment
labels:
app: azdevops-agent
spec:
replicas: 1
selector:
matchLabels:
app: azdevops-agent
template:
metadata:
labels:
app: azdevops-agent
spec:
containers:
- name: azdevops-agent
image: <azdevops-image>
env:
- name: AZP_URL
value: "https://dev.azure.com/<organization>"
- name: AZP_POOL
value: "<agent pool name>"
- name: AZP_TOKEN
valueFrom:
secretKeyRef:
name: azdevops
key: AZP_TOKEN
volumeMounts:
- mountPath: /var/run/docker.sock
name: docker-volume
volumes:
- name: docker-volume
hostPath:
path: /var/run/docker.sock
Autoscaling with KEDA
After the deployment is created you need to create the ScaledObject in order for KEDA to start scaling the deployment.
To scale based on the queue length of an Azure Pipelines agent pool, you can use the azure-pipelines trigger as of KEDA v2.3.
apiVersion: v1
kind: Secret
metadata:
name: pipeline-auth
data:
personalAccessToken: <base64 encoded PAT>
---
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: pipeline-trigger-auth
spec:
secretTargetRef:
- parameter: personalAccessToken
name: pipeline-auth
key: personalAccessToken
---
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: azure-pipelines-scaledobject
spec:
scaleTargetRef:
name: azdevops-deployment
minReplicaCount: 1
maxReplicaCount: 5
triggers:
- type: azure-pipelines
metadata:
poolID: "1"
organizationURLFromEnv: "AZP_URL"
authenticationRef:
name: pipeline-trigger-auth
The default targetPipelinesQueueLength is 1, so there will be one agent for each job.
⚠ The Azure Pipelines scaler supports scaling to zero but you need at least one agent registered in the agent pool in order for new jobs to be scheduled on the pool.
Running Azure Pipelines jobs
After deploying the agent and the KEDA ScaledObject it is time to see the autoscaling in action.
First, check the current pods running in the deployment:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
azdevops-deployment-5854bbbf84-r86qv 1/1 Running 0 75s

Now let’s queue some builds.
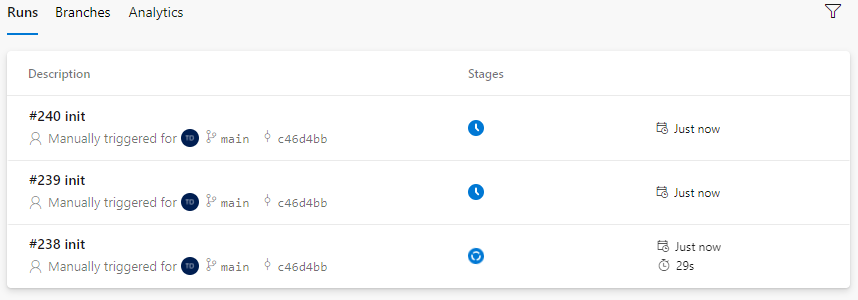
As a result, you see that KEDA starts scaling out the pods to meet the pending jobs:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
azdevops-deployment-5854bbbf84-4gfbx 1/1 Running 0 36s
azdevops-deployment-5854bbbf84-r86qv 1/1 Running 0 12m
azdevops-deployment-5854bbbf84-tm47k 1/1 Running 0 36s
And they appear on Azure Pipelines as well:
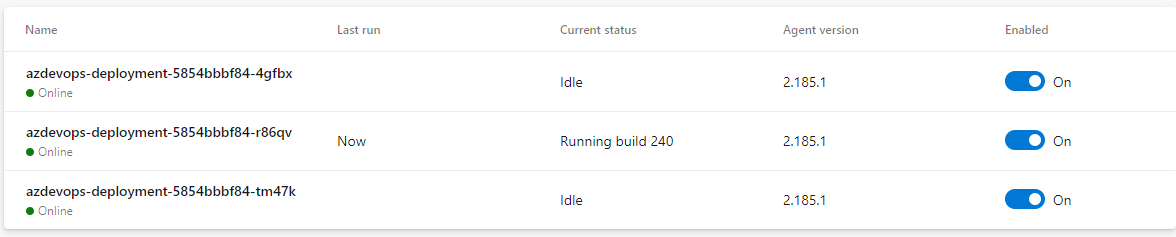
Run the self-hosted agent as a Job
When running your agents as a deployment you have no control on which pod gets killed when scaling down. (see KEDA docs)
If you run your agents as a Job, KEDA will start a Kubernetes job for each job that is in the agent pool queue. The agents will accept one job when they are started and terminate afterwards.
Since an agent is always created for every pipeline job, you can achieve fully isolated build environments by using Kubernetes jobs.
The following manifest is an example of a ScaledJob combined with the Azure Pipelines agent.
You have to use a modified image for this where the agent terminates itself after running a job. (docs)
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: azdevops-scaledjob
spec:
jobTargetRef:
template:
spec:
containers:
- name: azdevops-agent-job
image: <azdevops-image>
imagePullPolicy: Always
env:
- name: AZP_URL
value: "<organizationUrl>"
- name: AZP_TOKEN
value: "<token>"
- name: AZP_POOL
value: "<agentpool>"
volumeMounts:
- mountPath: /var/run/docker.sock
name: docker-volume
volumes:
- name: docker-volume
hostPath:
path: /var/run/docker.sock
pollingInterval: 30
successfulJobsHistoryLimit: 5
failedJobsHistoryLimit: 5
maxReplicaCount: 10
scalingStrategy:
strategy: "default"
triggers:
- type: azure-pipelines
metadata:
poolID: "1"
organizationURLFromEnv: "AZP_URL"
personalAccessTokenFromEnv: "AZP_TOKEN"
Placeholder agent
You cannot queue an Azure Pipelines job on an empty agent pool because Azure Pipelines cannot validate if the pool matches the requirements for the job.
When you try to do this you will encounter the following error:
##[error]No agent found in pool keda-demo which satisfies the specified demands: Agent.Version -gtVersion 2.163.1
You can, however, use a workaround to register an agent as a placeholder which allows you to queue jobs on an agent pool that has no agents that are online.
Make sure you don’t execute any cleanup code in your container to unregister the agent when removing it to keep the placeholder agent registered in the agent pool.
Seeing ScaledJobs in action
To allow scaling to zero and create agents on-demand, a template agent was created as a placeholder to be able to queue jobs.

Now, let’s queue some pipelines:
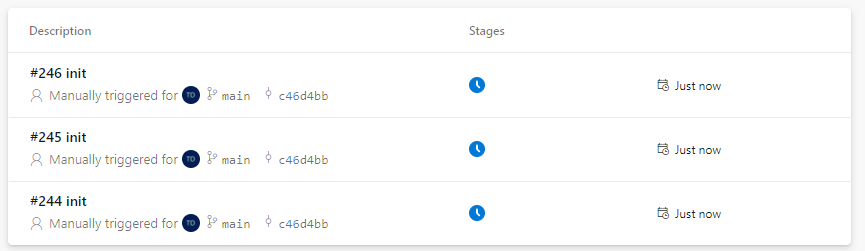
KEDA will create a Kubernetes job for each pending job in the queue for the specified agent pool.
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
azdevops-scaledjob-2hshf-mp5jl 1/1 Running 0 24s
azdevops-scaledjob-5gzr5-p8625 1/1 Running 0 24s
azdevops-scaledjob-mmlzc-rw5gm 1/1 Running 0 24s
Once that happens, you will see the agents are starting to process the pending Azure Pipelines jobs:
Once that happens, you will see the jobs in the Azure Pipelines’ agent pool:
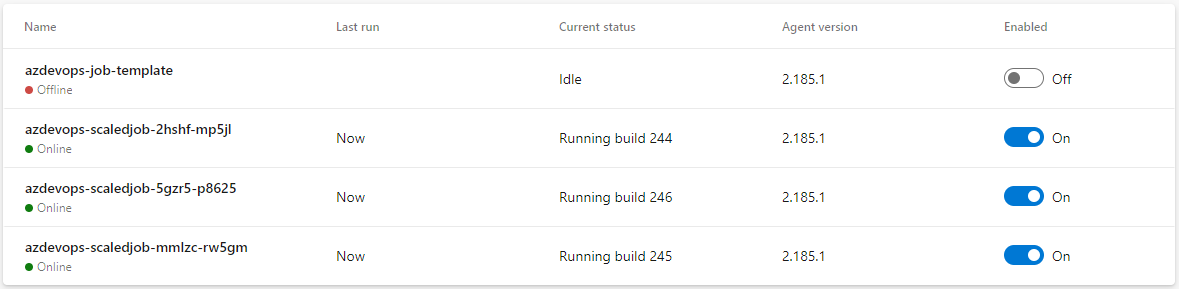
Using a ScaledJob is the preferred way to autoscale your Azure Pipelines agents if you have long-running jobs.
The other option is using a deployment and leveraging the container lifecycle. (docs)
Recent posts
Google Cloud deprecationsKEDA is graduating to CNCF Graduated project 🎉
Securing autoscaling with the newly improved certificate management in KEDA 2.10
Help shape the future of KEDA with our survey 📝
Announcing KEDA v2.9 🎉
HTTP add-on is looking for contributors by end of November
Announcing KEDA v2.8 🎉
How Zapier uses KEDA
Introducing PredictKube - an AI-based predictive autoscaler for KEDA made by Dysnix
How CAST AI uses KEDA for Kubernetes autoscaling
Announcing KEDA HTTP Add-on v0.1.0
Autoscaling Azure Pipelines agents with KEDA
Why Alibaba Cloud uses KEDA for application autoscaling
Migrating our container images to GitHub Container Registry
Announcing KEDA 2.0 - Taking app autoscaling to the next level
Give KEDA 2.0 (Beta) a test drive
Kubernetes Event-driven Autoscaling (KEDA) is now an official CNCF Sandbox project 🎉